How to Build Simple Web Scraper using Python
Web scraping refers to the process that allows users to scrape or extract data from any type of website. To compile the contact information from web directories one of common and basic method used is to “copy paste” information onto excel. This is very tedious and a time consuming process and is limited to small data needs. However, gathering bulk data from complicated websites requires sophisticated and automated methods, and expertise of professionals.
Web scraping could be performed using a “web scraper” or a “bot” or a “web spider” or “web crawler” (words used interchangeably). A web-scraper is a program that is automated to go to web pages, and download the contents. It then extracts specific data from the content and saves the data to file or a database.
Why do we need Web Scraping?
Today, Data is the oil that fuels any business. Businesses whether small, medium or large size greatly depends on Data for their decision making, to survive and also thrive. Since Data is the central dogma of any business it not only has to be extracted faster but it also has to be of prime quality, in order to stay up to date.
On the other hand Manual work/ “Copy-Paste” an ideal option for smaller data needs fall short when it comes to large data requirements. The process is time consuming, slow and also prone to errors. Let us imagine your business requires the details of thousands of products from an Ecommerce website. With scores of data available, manually copy pasting will take time as well as the data may become out-dated by the time you try to complete the scores of data on the website.
The ideal move for bulk data or complicated websites therefore needs to be automated and that is what a web scraper precisely does.
The Internet would be far less useful and terribly small without Web Scraping. The lack of availability of “real integration” through APIs has turned Web Scraping into a massive industry with trillions of dollars in impact on the Internet economy. The amount Google alone contributes to this number – not just Google’s revenues but all companies that rely on this “search engine”. McKinsey invested 8 trillion dollars in 2011 and it has increased exponentially since then. There is an enormous amount of data “available” on the Internet but it is hardly “accessible”. Google is the biggest web crawler in the world and today almost all of the web depends on it.
Difference between Web Scraping and Web Crawling
“Web Scraping” and “Web Crawling” both these terms are used interchangeably by most people. Although the underlying concept is to extract data from the web, they are different.
Web Crawling mostly refers to downloading and storing the contents of a large number of websites, by following links in web pages. Whereas a Web scraper is built specifically to handle the structure of a particular website. The scraper then uses this site-specific structure to extract individual data elements from the website. The data elements could be names, addresses, prices, images etc.
Uses of Web Scraping
People use web scrapers to automate diverse manner of data retrieval. Web scrapers along with other programs can do almost anything that a human does in a browser. They can order your favourite food automatically when you hit a button, buy the tickets for a concert automatically the moment they become available, scan an e-commerce website periodically and text you when the price drops for an item, etc. Infinite possibilities exist for any type of requirement in the realm of Web scraping.
How a Web Scraper Work
A web scraper is a software program or script that is used to download the contents (usually text-based and formatted as HTML) of multiple web pages and then extract desired data from it.
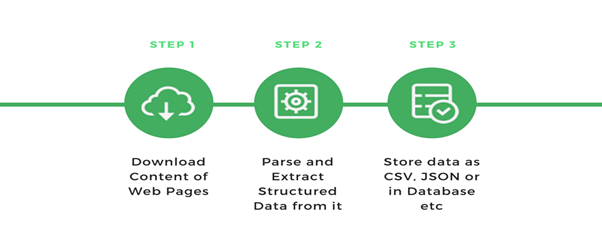
Components of a Web Scraper
Web scraping is like any other Extract-Transform-Load (ETL) Process. Web Scrapers crawl websites to extract data, and transform it into a usable structured format. Finally it can be loaded into a file or database for subsequent use.
A typical web scraper has the following components:
- A web crawler module
- An extractor or a parser module
- A data transformation and cleaning module
- Data Serialization and Storage Module.
First Scraper
Les get to programming and create our very first simple scraper. To do that we will use urllib python library. We will go to this page https://pythonscraping.com/pages/page1.html and scrape all the text from there. Below is the code and output:
Import Library:
from urllib.request import urlopen
Send a request using urlopen
html = urlopen('https://pythonscraping.com/pages/page1.html')
Read the scraped data:
print(html.read())
Output:

So this was our first scraper. Wasn’t that Easy!
If we notice, the page data scraped was in Latin and that is because the page was written in Latin. But our browser has the capability to translate Latin to English. But right now our Scraper does not have this capability. Going forward we will learn how we can make our scraper more advanced to do translation and much more.