Web Scraping Walmart using Python
Web Scraping Walmart using Python
Send download link to:
Walmart is the biggest retail chain in the world. With their brick and mortar stores they also have an ecommerce website. They have millions of products on their website under thousands of categories like electronics, clothing, shoes, furniture etc. Web scraping Walmart is necessary to extract this bulk data from it.
In This tutorial we will go to Walmart.com and scrape some products data from this site. With millions of products there is tb’s of data available related to those products on Walmart. This data can be used in numerous ways for example one can keep track of a product’s price and buy it when it drops to their level, can track a products availability, if you area seller you can keep a track of prices posted by other sellers and change your price accordingly, an ecommerce competitor can track product pricing and change accordingly, we can scrape customer reviews and ratings about a product and do an analysis on it etc. Look at our next tutorial for more on Walmart review scraper to scrape walmart reviews using Python.
So, there are numerous application of the huge amount of data that Walmart has. It is essential to know how we can grab this data and use it. So let’s learn web scraping walmart data.
In this tutorial we will go to this Walmart page https://www.walmart.com/browse/personal-care/hand-soap/1005862_1001719?page=1 and scrape the details of the hand sanitizers available there.
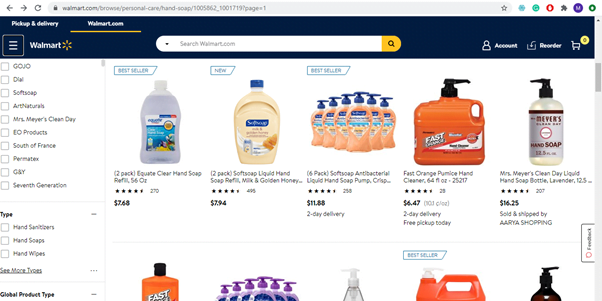
We will scrape details like item name, price, number of reviews, avg rating. See the complete code below or watch the video for complete explanation:
import requests
from bs4 import BeautifulSoup as soup
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'}
#create a url list to scrape data from all pages
url_list = []
for i in range(1,26):
url_list.append('https://www.walmart.com/browse/personal-care/hand-soap/1005862_1001719?page=' + str(i))
Output:

#Create empty list to store the data
item_names = []
price_list = []
item_ratings = []
item_reviews = []
for url in url_list:
result = requests.get(url)
bsobj = soup(result.content,'lxml')
product_name = bsobj.findAll('div',{'class':'search-result-product-title gridview'})
product_rating = bsobj.findAll('span',{'class':'seo-avg-rating'})
product_reviews = bsobj.findAll('span',{'class':'stars-reviews-count'})
product_price = bsobj.findAll('span',{'class':'price display-inline-block arrange-fit price price-main'})
for names,rating,reviews,price in zip(product_name,product_rating,product_reviews,product_price):
item_names.append(names.a.span.text.strip())
item_ratings.append(rating.text)
item_reviews.append(reviews.text.replace('ratings',''))
price_list.append(price.findAll('span',{'class':'visuallyhidden'})[0].text)
# creating a dataframe
import pandas as pd
df = pd.DataFrame({'Product_Name':item_names, 'Price':price_list, 'Rating':item_ratings,'No_Of_Reviews':item_reviews}, columns=['Product_Name', 'Price', 'Rating', 'No_Of_Reviews'])
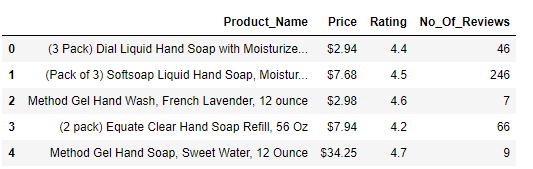
df.head()
Output of Walmart Scraping:
Hope you this tutorial is helpful for you, if any doubt then feel free to contact us. If you are interested in bulk data extraction from walmart, then we can scrape fresh data for you for product analysis. Once look at our sample data of Walmart scraper.