How to Download PDF using Python Web Scraping
How to Download PDF using Python Web Scraping
Send download link to:
Not all the data that we want to scrape is available as text on web. Sometimes we want to scrape data that is in form of files like PDF such as a book, a research paper, a report, a thesis, stories, company reports or simply any other data compiled and save as PDF file. In this tutorial we will learn about how to download PDF using Python.
Generally these data are large in size and it is not easy to download by a simple get request. This is because the HTTP response content (.content) is nothing but a string which is storing the file data. So, it won’t be possible to save all the data in a single string in case of large files. To overcome this problem, we need to incorporate few alterations to our program.
requests.get() method takes an argument called stream which if set to True will keep our session with server open. By default it is set to False. We need to use this hyper parameter to download large data files.

After doing this, Request library has a method .iter_content() which download large file in small chunks at a time. The size of the chunk is defined by user.
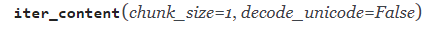
This method will create an itreable object from the response received by get request. When stream=True is set on the request, this avoids reading the content at once into memory for large responses. The chunk size is the number of bytes it should read into memory. This is not necessarily the length of each item returned as decoding can take place.
chunk_size must be of type int or None. A value of None will function differently depending on the value of stream. stream=True will read data as it arrives in whatever size the chunks are received. If stream=False, data is returned as a single chunk.
Below is the code for download PDF using Python. Do watch the video for detailed explanation.
import requests
file_url = "http://codex.cs.yale.edu/avi/db-book/db4/slide-dir/ch1-2.pdf"
r = requests.get(file_url, stream = True)
with open("python.pdf","wb") as pdf:
for chunk in r.iter_content(chunk_size=1024):
'''
writing one chunk at a time to pdf file
'''
if chunk:
pdf.write(chunk)
This script will send a get request to file url and then create a file named python.pdf in your working directory and write the downloaded content to it. More interested on How to Read PDF File using Python Web Scraping